April quick-takes
Recap of my short posts on LinkedIn in April
A Big Week for LLMs: Gemma 4, Qwen, Cursor 3, and a Claude Code Leak
A lot of LLM excitement this week: Google/DeepMind released Gemma 4, Alibaba unveiled Qwen 3.6-Plus, Cursor has a big new release (v3), Anthropic leaked Claude Code source, and even Microsoft released some new models.
The Gemma 4 release, latest in Google's line of small open models (from 2B to 31B parameters — not to be confused with its large Gemini model series), generated much buzz and excitement in the community. A big reason is the license switch to Apache 2.0, clearing some legal blockers for wider (re)use.
I tried Gemma 4 via llama.cpp and ollama, in multiple sizes, and wasn't very impressed: it did poorly on my simple Minesweeper coding tests and happily hallucinated about facts it didn't know about. Maybe it's the quantization or something with my setup, but it performed worse than Qwopus (Qwen3.5 plus distilled Opus 4.6) of similar size.
Speaking of Qwen, Alibaba also released an update, Qwen3.6-Plus. This, like Qwen3.5-Plus, is not an open model, but they did promise smaller open variants soon. I expect it's going to be a solid incremental improvement on an already great model.
In the land of coding agents, the new Cursor 3 shifts the UX to more “managing your agents” style, closer to what Claude Code app/web are doing, and away from “AI in your IDE”. You can still do that, but it looks like it's not their focus going forward, begging the question — why use Cursor at all?
Meanwhile, Anthropic is playing DMCA whack-a-mole with Claude Code leaked source code repositories on GitHub. Moreover, there are several projects that attempted “clean room” reimplementation — generate detailed PRDs/specs for the product from the code, then generate a clone from those specs without looking at the code.
Considering you can't copyright algorithms, data structures, or architectural patterns in software, it's going to be interesting to see how that story unfolds.
Oh, and apparently Microsoft also released some foundation models, but nobody noticed. To quote HuggingFace's CEO: “If it's not either pushing the frontier meaningfully or open-source, no one will care these days.”
What Is TurboQuant, Actually?
Two weeks ago, Google published TurboQuant research that promises to make LLMs more memory-efficient, triggering jitters in RAM prices. But what is TurboQuant actually?
Let's backtrack a bit to give you a better context: the defining feature of modern AIs is something called “attention”: a mechanism by which every token in a chat is influenced by every previous token (the tokens are “paying attention” to the preceding content).
To calculate this, you have to do some matrix multiplications of every token with every other token, for every new token (I'm simplifying a bit here). To do this naively would take a really long time, so LLMs have something called “KV cache” (you can think of it as “attention cache”), caching the multiplication results, speeding up the operation at the cost of a large memory increase.
The larger the context window, the larger the KV cache you need. How large? It depends on the model, but for smaller LLMs, the KV cache can easily be larger than the model weights!
Another important LLM detail you need to be aware of is “quantization”. Basically, the numbers (weights, KV cache, etc) in a neural network are floating-point numbers. The higher the precision, the better the quality and the more memory you need to hold the number. Standard precision used in LLMs is 16 bits, meaning each number takes up 2 bytes. But there are cases when you can lower precision without much quality loss. If you run a “Q4KM” model, you're using numbers quantized to 4-bit. Although there's research using 1.58 bits (ternary LLMs), in most cases even 4 is a big quality drop and everything below is unusable.
This is where TurboQuant comes in. With a really simple and clever mathematical trick, the researchers can drop the required precision for the KV cache to 3 bits with negligible quality loss and virtually no overhead.
What's the trick?
Each KV cache value is a vector of floating-point numbers. A peculiar property of those vectors is that some dimensions (members) have a large absolute value and some very small. Thus, when you reduce the precision of the floats, you destroy a lot of information across the dimensions that had smaller numbers. The trick is to “rotate” the vectors — matrix-multiply them with an arbitrary vector. This has the effect of making the dimensions roughly all the same scale — meaning when you reduce precision, you reduce it for all numbers roughly the same, and by a larger amount. (If this is fascinating, there's an even better trick, 1-bit residual — read the paper to find out!)
When implemented in an LLM, this means you can run it on smaller hardware, it's faster (because memory bandwidth is usually the limiting factor), or with larger context windows.
Will this lead to RAM prices collapsing? I wish! But no — everyone wants larger context windows :) It's yet another important but incremental step in making modern LLMs even better.
Don't Reward Token Burning
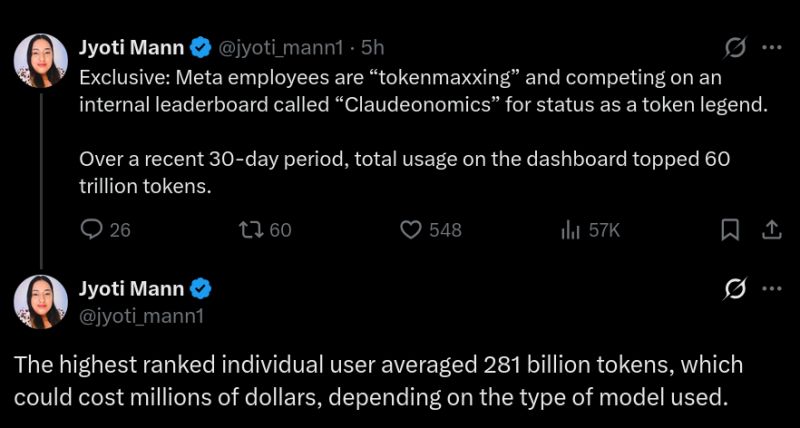
This is wrong on so many different levels:
- any metric will be gamed (Goodhart's Law)
- “more = better” is rarely correct in software development
- “tokenmaxxing”, wasting as much resources as possible, is totally braindead as a metric
- Meta being Meta, they had to gamify it to increase engagement
Now instead of trying to build better software, developers are burning through trillions of tokens and billions of dollars to become “a token legend” (presumably there's some sort of a prize as well).
Would anyone actually caring about their craft want to work in an environment like this?
If you're in a technical leadership position and your org wants to “incentivize AI adoption” by reporting (or worse, rewarding) token usage — do not do this. This is likely the worst possible way to approach it, and will cause lasting damage to your org.
Source: Meta employees vie for “AI token legend” status
The Mythical Claude Mythos and AI Vulnerability Research
Anthropic says they have an awesome new model, Claude Mythos, that's so powerful they won't publicly share it. We've seen such marketing gimmicks before, but security-minded researchers and developers are taking LLMs seriously.
The new model is supposedly trouncing everything else on various benchmarks and has produced “thousands of high-severity vulnerabilities, including some in every major operating system and web browser.” To avoid proliferation of thousands of 0-day exploits, Anthropic is only making it available to “launch partners” to use it “as part of their defensive security work”.
Sounds like boasting, and I'm skeptical of such unfalsifiable claims. However, both the Linux and FreeBSD kernels have recently patched bugs that have possibly been surfaced by the new model. Simon Willison did some digging and has a good overview of the situation.
Recently Linux kernel maintainers, authors of popular open source software (like Daniel Stenberg, author of curl, who's pretty much against AI slopware), and various security researchers have been talking about LLMs becoming really good at finding security problems — see Vulnerability research is cooked.
As Thomas Ptacek says in that blog post: “I think we're living in the last fleeting moments where there's any uncertainty that AI agents will supplant most human vulnerability research.”
Now I really want to see that mythical beast.
Embarrassingly Simple Self-Distillation
Here's an interesting AI paper Apple released last week: Embarrassingly Simple Self-Distillation Improves Code Generation.
Accepted wisdom around LLM training is that you can't use LLM output to train the same LLM: if you try to do that (without improving, validating or cleaning the output in some other way), the LLM will get dumber and dumber. This is called model collapse and was documented in a 2024 paper, “AI models collapse when trained on recursively generated data.”
Turns out, it's not necessarily true. The new Apple paper does exactly that, in a specific domain (code generation), and the model keeps improving! From the paper:
Sample solutions from the base model with specified temperature and truncation, then fine-tune on those raw, unverified samples via standard cross-entropy loss. This method requires only a set of problem prompts and the model itself: no human-labeled solutions, no reference answers, no teacher model, no reward model, no verifier, no execution environment, and no reinforcement learning of any kind. Surprisingly, it works.
To anyone knowledgeable about how LLMs work, this makes as much sense as a perpetual motion machine. It shouldn't work. But it does! Why?
Code generation is a type of problem where the LLM must work in two different ways: “fork” mode that creatively thinks of possible solutions, and “lock” mode which has to correctly implement the chosen solution. These two modes require different “temperature” (or “creativity”) levels, but temperature is a single global setting, so it's always sub-optimal.
The self-distillation approach samples solutions with different temperature settings, nudging the model in different directions, then teaches it those approaches. This doesn't add any new information into the system, but helps the model better organize the information it already has.
The method really is embarrassingly simple — it doesn't even test whether the generated code is correct (which is pretty easy to do with code!). I'm sure this will be picked up by all AI labs to improve coding capabilities. And I wouldn't be surprised if someone manages to generalize it to other domains.
(PS. The paper was released on April 1st, but apparently is not an April Fools' joke, I checked :)
Claude Opus 4.7
Anthropic released Claude Opus 4.7, an incremental improvement to their existing 4.6 model (still not the mythical Mythos everyone's been talking about lately).
I took it for a quick spin using my “LLMCraft” test. It built a pretty solid (bare-bones) WarCraft/StarCraft clone. There were a few bugs which I pointed out in one message, and it managed to solve them in the response. (Playable version, code.)
(Note: my prompt calls for a single-user version with no enemies, just one level, no sound; multiplayer and enemies I want to leave as a challenge for 2027 :)
Besides the incremental improvements across the board (see benchmarks in their post — but take them with a grain of salt, as always), the highlights are an extra-high-effort option, a fix for Claude ignoring instructions (especially in CLAUDE and memory files), and vision improvements.
Speaking at SaaStanak 2026

Happy to announce I'll be speaking at SaaStanak 2026!
Honored to join an impressive roster of speakers covering GTM, Product, Engineering and more. I'll be talking about my experience leveraging AI to build a startup MVP in days instead of weeks or months.
Vibe coding, and AI in general, is impacting everything. But clarity of vision, human judgement, good taste and business sense are more important than ever, and these are exactly the topics explored at SaaStanak. I hope you'll join me!
28 Years of MicroLinux
This post is in Croatian
Prije točno 28 godina, napravio sam prvu hrvatsku Linux distribuciju — MicroLinux — sa idejom popularizacije Linuxa na domaćim prostorima.
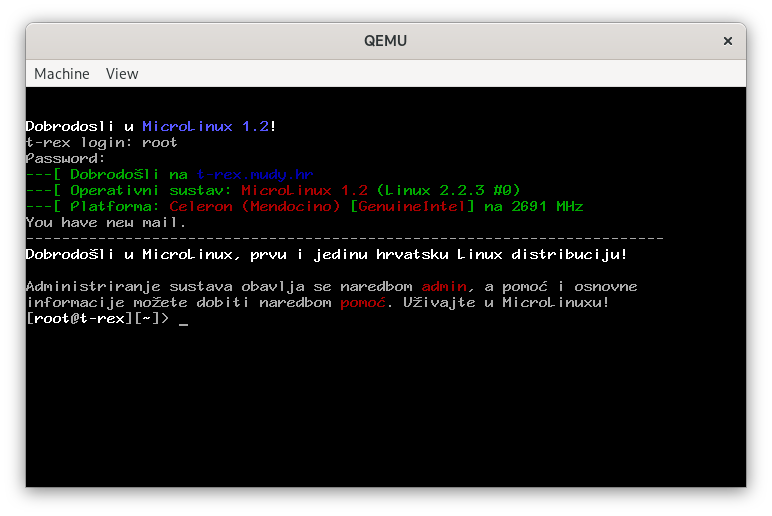
MicroLinux je bio mala distra (14MB), mogao se instalirati na postojeću DOS/Windows particiju, a pokretao se iz DOSa. Pojednostavljena (za to vrijeme) administracija sustava bila je na hrvatskom, a uz distribuciju je dolazila i prevedena dokumentacija i korisničke upute.
Godinu dana kasnije izdao sam verziju 1.2, koju sam predstavio i na prvoj DORS/CLUC konferenciji 1999. godine — moje prvo konferencijsko predavanje (true story: nisam znao da se obično pripreme neki slideovi pa sam pričao “na suho” :)
Ovaj vikend ponovno dolazim na DORS/CLUC pa sam se tom prilikom prisjetio MicroLinuxa i uspio iskopati stare arhive (nažalost samo verziju 1.2 — prvu verziju imam negdje na Bugovom CD-u, uključili su je na jedan od prvih CD-ova uz časopis, ali ga nisam nigdje uspio naći).
MicroLinux je dugo bio dostupan na linux.hr serverima (hvala HULK-u na podršci od prvog dana!), a sad sam ga preselio na senko.net/microlinux zajedno sa QEMU slikom diska za jednostavno isprobavanje unutar emulatora.
Three New Chinese Models
Three new open(-ish) Chinese models have been released, to much hype, in the past couple of days: Kimi K2.6, Qwen 3.6-Max-Preview, and (two weeks ago) GLM-5.1.
All three are big & closed models, but promise smaller, distilled, open versions will be out soon. All three excel at various benchmarks and are pretty hyped up by the open-weights crowd, placing them neck-and-neck with the latest models from OpenAI and Anthropic.
That's an exaggeration. I haven't done much testing yet, but what I saw was good performance but not really comparable to the latest & greatest. Subjectively, they feel closer to last year's SOTA crop. And of course, if you run a smaller open variant, there's an additional quality hit.
But that might not matter for some cases. These new models, across the board, are now good enough for many tasks that don't really require the best model out there. With that caveat, they can be used for coding, agentic workflows, chatbots and many other simpler tasks.
Whether that's cost-effective is another matter. Renting or buying your hardware is still a pretty pricey option: if you just rent a GPU for a month and serve a model from there, it's probably going to cost more than paying for the tokens for a model of equivalent quality. OpenRouter is another option, but is slightly a mess — finding a reliable provider there is not easy.
However, these new models still represent a solid “Plan B” in case the major providers jack up the prices, implode, or start banning uses (like cybersecurity research) left and right.
Links: GLM-5.1, Qwen 3.6-Max-Preview, Kimi K2.6.
Claude Code Goes Max, SpaceX Eyes Cursor
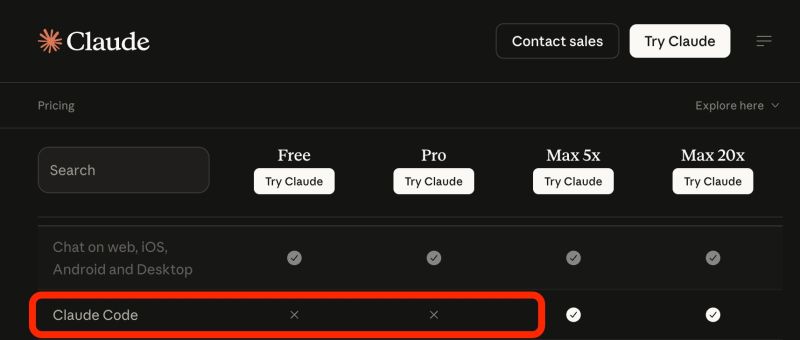
Anthropic might soon require a Max subscription for Claude Code; meanwhile, SpaceX buys an option to acquire Cursor for $60B.
Anthropic is A/B testing subscription purchase workflows that seem to indicate users won't be able to use Claude Code with a ($20/mo) Pro plan. Instead, it would only be supported for Max plans ($100+/mo).
Anthropic just doesn't have enough capacity for the huge demand growth they've been experiencing. They've already been setting strict limits which, according to many users, have made Claude Code unusable on Pro plans. They've also banned subscription use with other dev tools (like Pi), OpenClaw and similar tools. And we've known for a long time that subs are subsidised. So this is nothing unexpected.
Yet even a hint already caused a lot of uproar. They pedaled back slightly, but a lot of the developer goodwill Anthropic has gained is getting burned. If OpenAI play their hand right, they might draw a bunch of devs back to Codex. And of course there's also Google with Antigravity, and a bunch of solid Chinese models (Cursor's in-house coding LLM is a fine-tuned Kimi K2.5, and a new Kimi was just released the other day).
(As an aside: startup founders, if you've ever wondered how post-product-market-fit demand can hurt you — here's how: you can easily collapse under the weight of it; let's hope that doesn't happen to Anthropic.)
Meanwhile in rocket land, SpaceX will “work closely with Cursor” and has an option to acquire it wholesale for a trifling $60B (for context, Musk bought Twitter for $44B).
Nothing to do with rockets, of course — SpaceX is now a conglomerate containing Twitter and xAI, and a reasonable reading of the deal is that Musk is looking for synergies between xAI and Cursor.
Now for the tough one: since the X-Code and CodeX brands are already taken, I wonder how Cursor would be (re)branded post-acquisition?
Local Models Are Now Good Enough for Coding
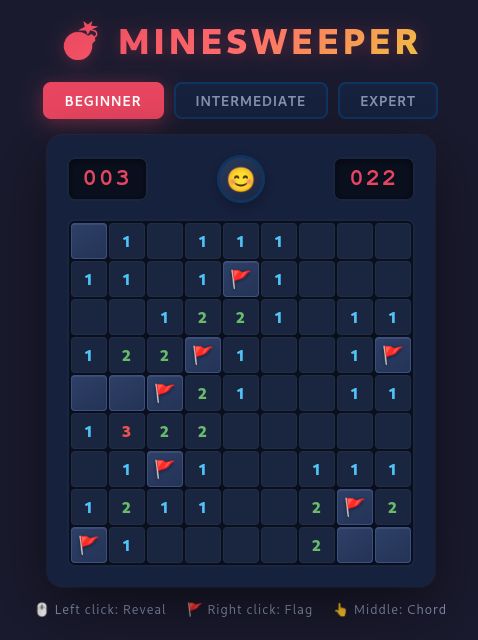
The local models are becoming good enough for coding. I've tested the newly released Qwen3.6-27B model on a local machine with my Minesweeper task, and it did about as well as Opus 4.5 from a few months ago.
I retired my Minesweeper tests at the end of last year because all models completed it successfully. All large models, that is. Local models, up to ~30B params, still had a lot of trouble.
This is now changing, and if you have beefy enough hardware, local models are now a viable alternative for coding tasks. I took the new Qwen3.6 with 27B parameters (quantized to 4 bits-per-param) for a spin.
It did a perfect Minesweeper implementation, subjectively (from a user POV) equivalent to what Opus 4.5 did in December. Not only that: Claude Code (Opus 4.7) and Codex (GPT-5.4) reviewed Qwen3.6-27B's vs Opus 4.5's output and both identified Qwen's output as much better. Check for yourself: Qwen, Claude.
This is a limited-scope test. Opus likely performs much better on large-scale projects (which I intend to test), and you need a beefy machine to run it at a reasonable speed (my own test was pure CPU+RAM, taking half an hour to generate it — you definitely want a large VRAM GPU or a Mac for actual use).
But, still. For the first time, unless you're vibe-coding complete features in one prompt, new models like Qwen (or the recently released Kimi K2.6) may be just good enough to switch, especially if you dislike the pricing shenanigans Anthropic is doing.
DORS/CLUC 2026 Recap

Had a wonderful time yesterday and today at DORS/CLUC 2026. There were many interesting talks and discussions, but the highlight for me was the hallway track!
I had a chance to see a few of the talks (had to miss several, sadly — will catch up when they're published online), participate on two panels and present the Cijene API project. I especially enjoyed Luka Kladarić's talk about the impact of AI on open source and the challenging questions for us all — I was so focused on the talk I forgot to snap a picture :)
I again met many old friends (some of whom I haven't seen in decades!), reminisced about the old days and caught up on what's new. For example, did you know we have a hardware fab right here in Croatia? (tinkerfab.net)
I also met new friends and was heartened to see newer generations of free and open source and open data enthusiasts involved in various projects.
Thank you for having me, DORS/CLUC — see you next year!
Coding Model Shootout: GPT-5.5, Kimi, DeepSeek, Qwen
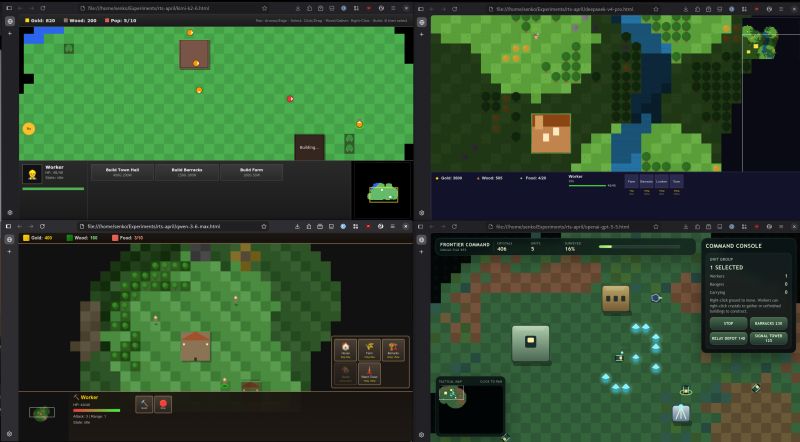
There have been a bunch of capable coding models released recently: GPT-5.5, Kimi K2.6, DeepSeek V4 and Qwen 3.6 Max (Preview). I've run them all through my new LLMCraft benchmark.
GPT-5.5 is the best of the bunch by far, no question there. It's tied with Claude Opus 4.7, which I reviewed last week.
Qwen also did pretty well, while both DeepSeek and Kimi produced a less polished and more buggy experience. However, all three managed to produce a solution more-or-less to spec.
- Kimi K2.6 (top-left)
- DeepSeek V4 Pro (top-right)
- Qwen 3.6 Max Preview (bottom-left)
- OpenAI GPT-5.5 (bottom-right)
Here's the kicker: ALL of these models were markedly better than GPT-5.3-Codex, released just 3 months ago.
I used GPT-5.5 with Codex CLI, Kimi and DeepSeek through Pi.dev with the official API, and Qwen 3.6 Max Preview via Qwen's chat interface (since I was unable to onboard myself to Alibaba Cloud Platform to get 1st-party API access to Qwen). In the first three cases I only specified the initial prompt (one-shot), while for Qwen I gave it a few bug reports (non-clickable buttons or JS errors) and allowed it to regenerate the output a few (three) times total to fix them, to compensate for the lack of an optimized coding harness.
Note that DeepSeek and Kimi are open-weights models at full sizes, while Qwen3.6 Max Preview is not (Qwen/Alibaba earlier released smaller 27B/35B 3.6 models under an open license).
Across all of these, the raw LLM coding capability is good enough to avoid being beholden to OpenAI, Anthropic or Google (for Gemini), which makes me optimistic about subscription/token prices staying sane (i.e. no large increases).
I can totally see a future where, should the cost of Claude or GPT increase five-fold, I switch to one of these alternatives and accept the quality hit for the budget option.
“The goblins kept multiplying.”
Curious users recently unearthed goblin-suppressing instructions in OpenAI's Codex CLI, prompting questions, intrigue and theories around the rationale behind it.
OpenAI spilled the beans in a fun, endearing and informative post: they had a goblin infestation. The goblins came quietly, an innocuous side effect of the fun & quirky personalities feature added in GPT-5.1. They, alongside their gremlin brethren, were given more prominence in the “Nerdy” personality. As OpenAI document:
We unknowingly gave particularly high rewards for metaphors with creatures. From there, the goblins spread.
Although they've cleaned up their training data to lower the incidence of goblins spontaneously materializing in your coding session, it was too late for GPT-5.4, which was already trained, so they applied a hotfix to the system prompt:
never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query
For fans of mythical creatures and strange beasts, the post does contain instructions for how to remove the hotfix — at least until the next major GPT version.