May quick-takes
Recap of my short posts on LinkedIn in May
Unlimited Power, Limited Focus
In the age of AI, focus is essential.
We now have, to quote Darth Sidious, unlimited power (subsidized by Anthropic and OpenAI). But we don't have unlimited focus.
In fact, many of us behave like squirrels on caffeine. We can run very fast, burning the midnight candle at both ends, wasting our time and tokens on stuff that, had we paused to think about it, would not pass muster.
Code is a liability — always has been. We're now printing the liability with such abandon that Leeroy Jenkins would look sheepish in comparison.
With everyone having this awesome tool at their disposal, how can you stand out?
- Use your judgement, wisdom, and taste.
- Focus. Keep your eyes on the ball.
- Understand that AI is a good servant, but a bad master.
And FFS, don't brag about burning tokens. Brag about what you've achieved with the tokens.
AI Is Technology, Not a Feature
If you run, or work for, a tech startup, you've seen this: customers, investors, and bosses ask you “do you have AI yet?”. There's a lot of unhealthy pressure to keep up with the competition and ship “AI features”.
AI is great technology, but it's not “a feature”. In fact, the best implementations out there are where you wouldn't even notice it (if it weren't so prominently showcased).
The fact of (startup) life is, you're pressured into both adopting and marketing your use of AI. It's on you to find the good use cases that fit nicely into your product.
I explore the conundrum in AI is technology, not a feature.
Code Review is Broken
In The agent principal-agent problem, David (cofounder of Tailscale, founder of Exe) raises an uncomfortable question: do we need code reviews?
This echoes Ankit's (founder of Aviator) How to kill the Code Review and Justin's (cofounder of StrongDM) Software Factories essays. In particular, Justin argues that “Code must not be written by humans” and “Code must not be reviewed by humans.”
I also touched on this in my Code reviews in the age of AI article a few months ago, where I argue we should put more emphasis on reviewing the plans/specs, and only do limited, targeted manual code reviews.
If you're leading a software engineering team and don't want to sacrifice quality for velocity, this question is worth thinking about, and discussing with your team.
Style Convergence in AI-generated Design

The curious case of the “contemporary Fraunces serif magazine editorial” design in Claude.
Here's what happened to me yesterday (all in one day):
I had to quickly whip up a website, and I turned to Lovable for some inspiration. The design looked nice but too close to FT/WSJ and even had some undertones of Anthropic.
So I fired up Claude Design and asked it to do the same (based on the same brief containing no design guidelines). The results looked eerily similar.
I fired up Claude Code (CLI). Same thing. I was sure I'd somehow triggered this with my website brief, even without actually specifying it.
Then I noticed a LinkedIn post from someone featuring a virtually identical design. Now I was sure it wasn't my prompting or something contaminating my agents' contexts.
This looked like a new version of the “Bootstrap design” effect, where AI agents mostly churn out similar pages. I told Claude to go in a completely different direction, and called it a day... or so I thought.
Because hours later, I saw the same damn design on Twitter, from none other than Peter Steinberger, author of OpenClaw, talking about vibe-slopped web pages.
To top it all off, in the evening I was helping my kid with some physics lessons and decided to create an interactive visualiser in Claude Web, to help with the understanding behind the math. Guess what: same friggin' design!
Now, I understand LLMs are not creative. But I also understand they are supposed to be non-deterministic, and this was pretty damn deterministic in my book!
I suspect the culprit is the combination of how Claude was trained, and Anthropic's “frontend-design” skill, which probably got loaded into all of those places. Lovable doesn't disclose which LLMs they use (to the best of my knowledge), but this would pretty strongly indicate Claude, and with the frontend skill enabled. As for why Claude prefers this: since it is similar to what Anthropic itself uses, I suspect there was some (unintentional?) stylistic or taste influence (leakage?) from their designers into the training data.
Whatever the cause may be, somehow, Claude overwhelmingly tends to converge on this type of design.
I mean, it's a nice design — it was nice once. Now I'm seeing it everywhere; it's like the em dash all over again.
Bun, Ported from Zig to Rust by AI
This is cool and scary: Bun, a JavaScript platform (alternative to NodeJS), has been (officially) ported from Zig to Rust using AI.
We've seen LLM-powered rewrites (chardet, justhtml) before. This is different because of scale. Bun is a large and much more complex project than either of those, and it was apparently ported in two weeks.
Projects at this scale (like Claude's Compiler or Cursor's browser) have so far been interesting experiments, but a far cry from production-ready code.
The merged PR has a million lines of new code, which presumably haven't been human-reviewed. A week ago the author claimed 99.8% of all tests passed (on Linux). Looks like it took them only a week to get to 100% across all supported platforms.
More quietly, a similar rewrite has been happening at Ladybird, a new browser with its own from-scratch engine (i.e. not just a wrapper for Chrome, Firefox, or another existing browser). It was originally written in C++, and they've started (slowly) porting it to Rust with AI's help — not automatically.
A few thoughts:
- first public, successful large-scale project using fully autonomous, non-reviewed AI — we'll probably see more
- robust test suites are a must — this would be a non-starter otherwise
- Rust, and to a lesser extent Go, are becoming the go-to languages for AI-assisted rewrites
- this would have been at least a year-long project without AI
Happy First Birthday, Cijene API
This post is in Croatian
🎂 Sretan rođendan, Cijene API! 🎂
Prije točno godinu dana stupila je na snagu Odluka o objavi cjenika, čime je Vlada RH obvezala velike trgovačke lance da dopuste automatsko preuzimanje (scraping) i obradu cijena.
Vidjevši tu objavu, pokrenuo sam Cijene API kao zabavan vikend projekt.
Godinu dana kasnije, podržavamo 29 trgovačkih lanaca, preko tisuću poslovnica, prikupljamo preko 10 milijuna cijena dnevno, a u ovih godinu dana prikupili smo ukupno preko 3 milijarde cijena.
Sve ovo javno je dostupno kroz naš API na cijene.dev i kroz dnevne arhive cijena.
Imamo nekoliko desetaka API korisnika (komercijalnih i nekomercijalnih), projekt pokriva svoje troškove servera, a imamo i malu, ali aktivnu zajednicu ljudi koji doprinose, što prijavom problema, što kodiranjem — hvala im od srca!
Posao nije gotov. Dok ovo tipkam imam jedan PR u pripremi za promjenu CSV formata jednog lanca i drugi PR za dodavanje još izvora. Serveri trgovačkih lanaca ponekad se ruše ili kasne s objavama. Naš API bi mogao biti još bolji.
Ali kroz ovu prvu godinu, mogu reći da su (posredno) stotine tisuća građana Hrvatske vidjele ili iskoristile informacije koje su prošle (na ovaj ili onaj način) kroz Cijene API.
Idemo dalje!
Running a Frontier LLM on Your Own Hardware
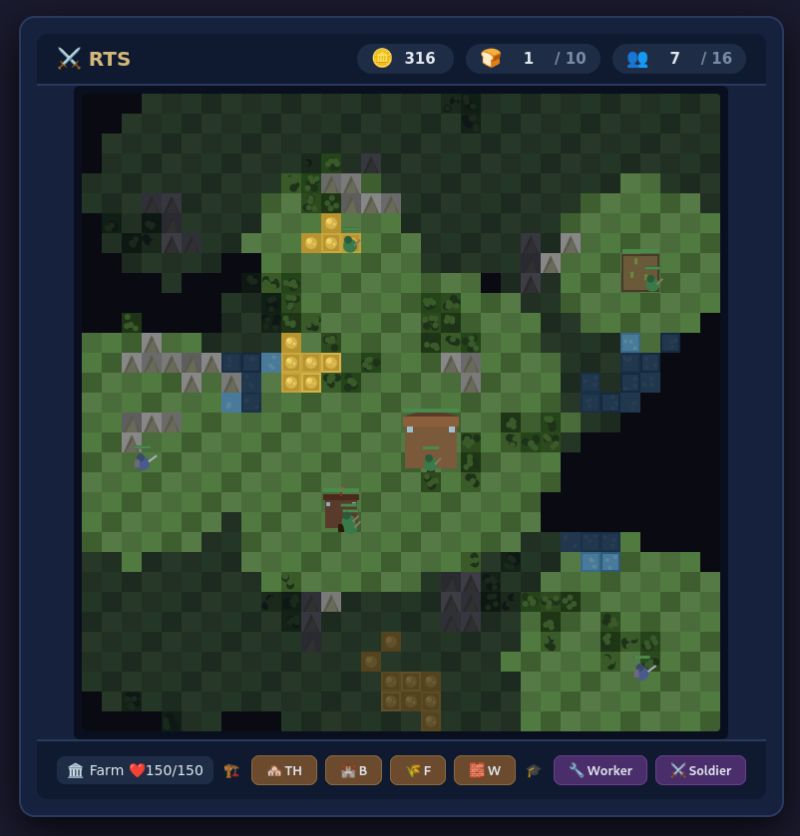
The shape of things to come: how to run a frontier-level LLM on consumer hardware. Salvatore Sanfilippo (a.k.a. Antirez, best known as the author of Redis) has been working on a new LLM inference engine (like llama.cpp, VLLM, or HF transformers), optimized for the DeepSeek V4-Flash model.
The DeepSeek V4-Flash is a smaller version of DS' newest model, released a few months ago, with 284B params, of which 13B are active, supporting a 1M context window.
What Antirez is doing with his project (dubbed DwarfStar 4) is to really push the hardware to its full extent, hyper-optimized for the model in question, whereas other engines are more generic and thus can't make tradeoffs to speed up one LLM version.
DwarfStar 4 (DS4) supports Metal (Apple) and CUDA (NVIDIA) architectures, with ROCm (AMD) on the way. But it also runs on CPU, if you're really patient.
The other piece of the puzzle is the hybrid 2-bit quantization for the model, i.e. using only ~2 bits for each floating-point parameter (down from the original 16). If you know how floating point works, this feat alone is mind-boggling, but it works, with noticeable but acceptable quality tradeoffs.
The end effect is that you can run DS4 on a machine with 96+ GB of VRAM, like the NVIDIA DGX Spark, or 96+ GB of unified RAM (like the Macs). Or, if you're really patient and only do it for testing — on ANY machine with 128GB of RAM.
Well, I'm patient and only do it for testing, and I happen to have 128GB of RAM, so I took it for a spin. Well, at ~1 token/s, “rotating slowly” would be a more apt term :) It's supposed to run at quite usable 20-30 t/s on Macs or Sparks.
It did a great Minesweeper (no surprise there), and a working RTS! Don't get me wrong, it was barely working and full of glitches. Much worse than the DeepSeek-V4 Pro version tested via the official API.
But — it's fully local. And it does work.
Now the only thing we need is a bit faster (and cheaper) hardware. Let's go, Moore, we're counting on you!
The Frog Has Already Been Boiled
People on LinkedIn, X, Facebook and Instagram are worried about the upcoming Google search UI change, removing the links to content sites. I'm here to tell you not to worry — the frog has already been thoroughly boiled.
For years, Google has been a steadfast partner for many — or most — commerce sites on the internet. Through SEO juice, paid ads, or actual word of mouth (remember that, anyone?), Google sent traffic to sites. Users were happy, sites were happy, Google was happy. Now that Google has a competent AI and all the data it can ask for, it doesn't need to link to sites so much.
AI is just the tip of the iceberg, but Google has been experimenting with this for years. Yet, like addicts, sites needed the juice fix, and did everything Google asked of them in the guise of “best practices”.
Now the other shoe dropped, chickens are coming home to roost, and the frog is cooked.
It gets better: LinkedIn, X, Facebook, etc. — all the places people use to voice this — are doing the same. Y'all are feeding LinkedIn with data (ironically, this post as well), and it's staying locked within its walled garden. One example: LinkedIn has recently stopped allowing non-authenticated browsers to even expand the links in posts (meaning I can't open a link in a private/incognito window, which annoys me to no end).
On X, you can't open a thread / see replies to a post unless you're logged in. Combined with pushing users to add links to outside pages in comments, you get a lock-in mechanism.
On Facebook and Instagram, you often can't see the post unless you're either on the app or logged in. I purposely do neither, and have no end of traffic lights, fire hydrants and bicycles to click through if I really want to see a shared post.
There's going to be a feast, and your content is on the menu.
Bon appétit!